Бесплатные аналоги FreeOCR
Официальный сайт программы
- Бесплатная
- Windows
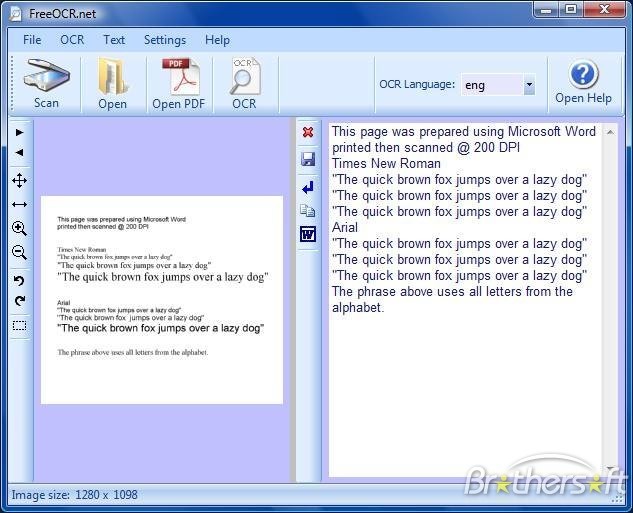
FreeOCR - это программа для сканирования и распознавания, включающая в себя движок Tesseract free ocr, также известный как графический интерфейс Tesseract.
Он включает в себя установщик Windows и очень прост в использовании. FreeOCR поддерживает многостраничные TIFF, факсимильные документы, а также большинство типов изображений, включая сжатые TIFF, которые механизм Tesseract сам по себе не может прочитать.
Может работать с форматами PDF, а также совместим со сканерами TWAIN.
Бесплатный механизм распознавания текста Tesseract - это находящийся в открытом доступе продукт, выпущенный Google. Он был разработан в Hewlett Packard Laboratories в период с 1985 по 1995 год. В 1995 году вошел в тройку лучших на конкурсе OCR, организованном Университетом Невады.
Бесплатные альтернативы для FreeOCR
-

-
Чистая библиотека JavaScript OCR.
- Бесплатная
- Windows
- Mac OS

Tesseract.js - это библиотека javascript, которая распознает слова практически любого языка из изображений.

-

-
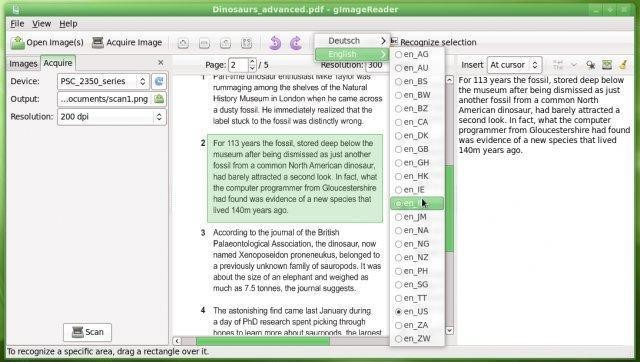
gImageReader - это простой интерфейс Gtk / Qt для механизма распознавания текста Tesseract.
- Бесплатная
- Windows
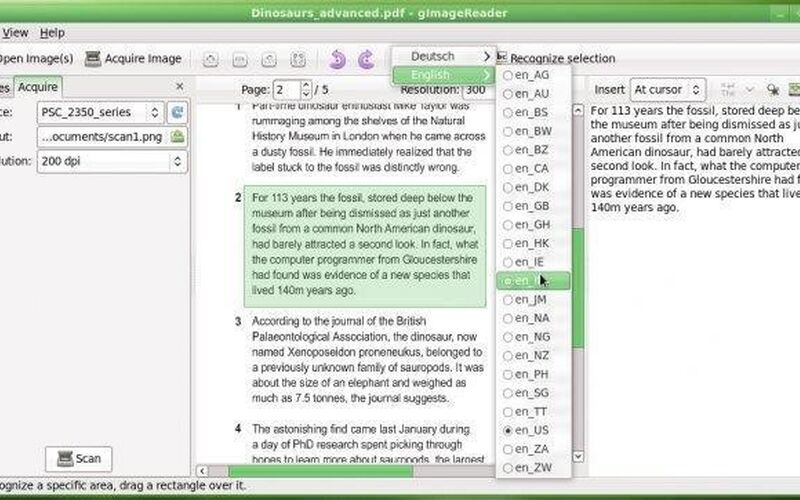
gImageReader - это простой интерфейс Gtk / Qt для механизма распознавания текста Tesseract.
-

-
Free Online OCR - это программа, которая позволяет конвертировать отсканированные PDF и изображения в редактируемые форматы.
- Бесплатная
- Онлайн сервис
Free Online OCR - это программа, которая позволяет конвертировать отсканированные PDF и изображения в редактируемые форматы: Word, Text, Excel.
-

-
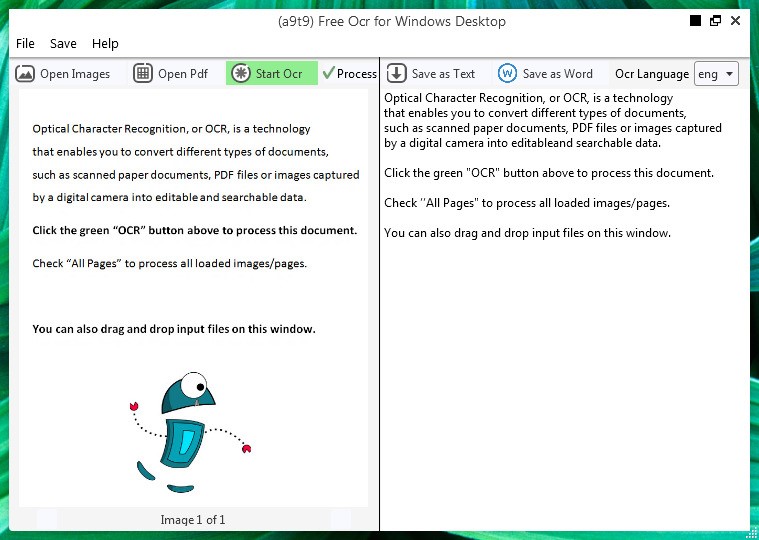
Бесплатное программное обеспечение с открытым исходным кодом и веб-сервис для извлечения текста из файлов изображений и PDF.
- Бесплатная
- Windows
- Онлайн сервис
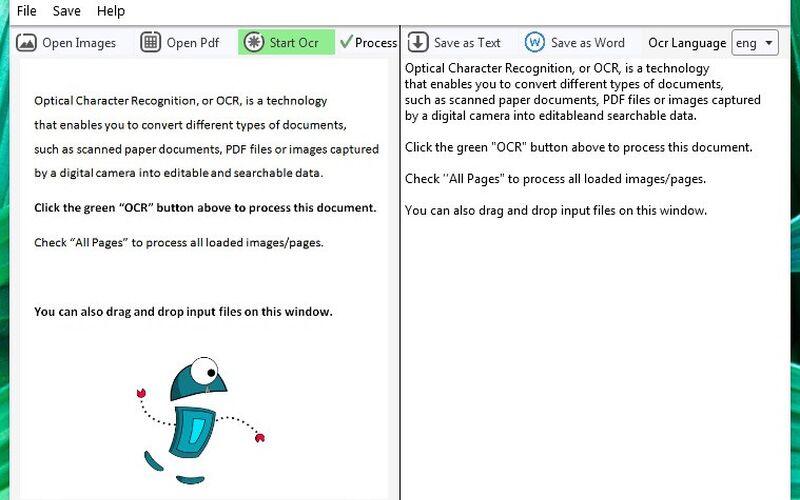
Это быстрое и бесплатное программное обеспечение для распознавания текста извлекает текст из файлов изображений и элементов PDF.
-

-
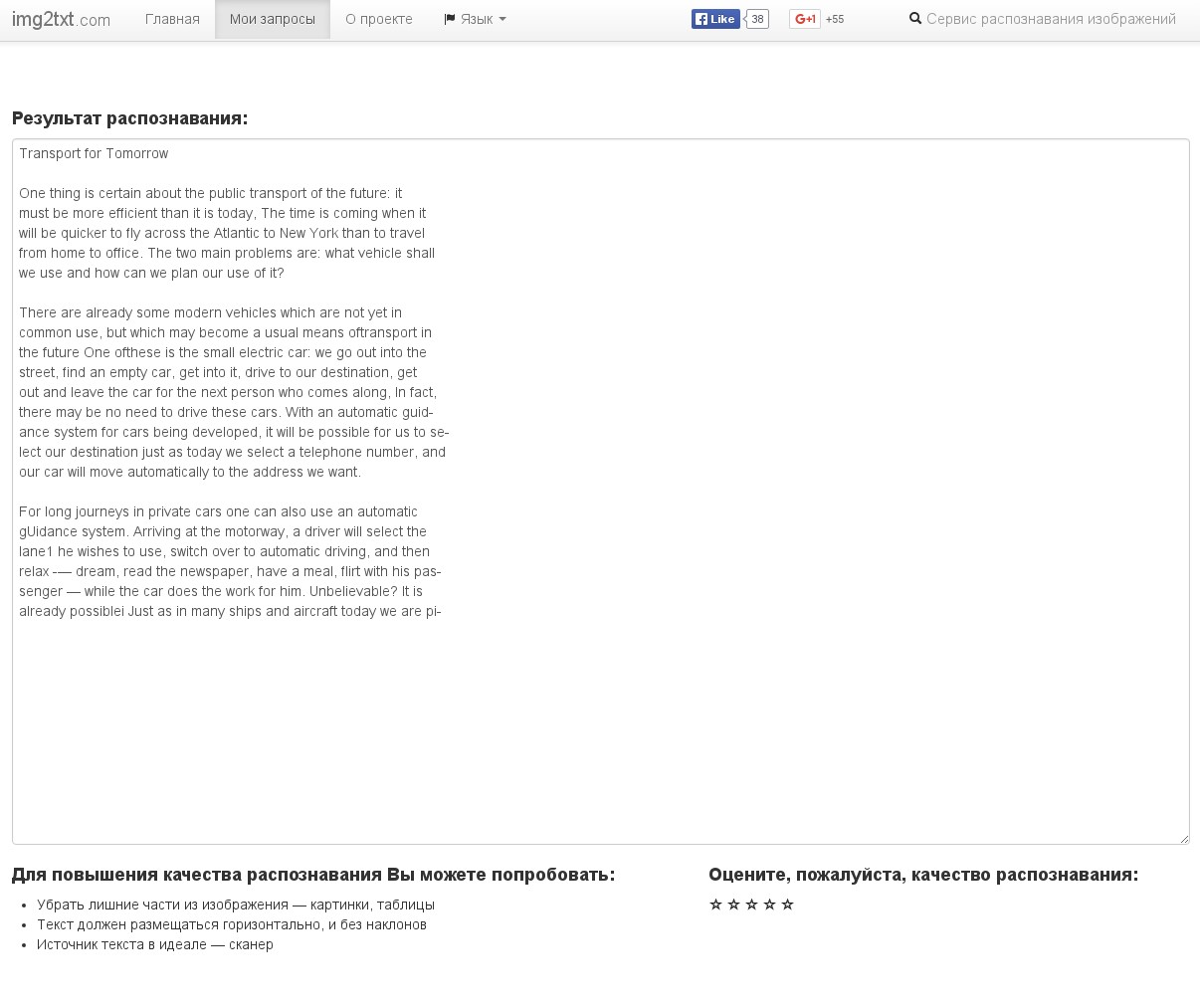
img2txt.com - это онлайн-сервис для распознавания текста.
- Бесплатная
- Онлайн сервис
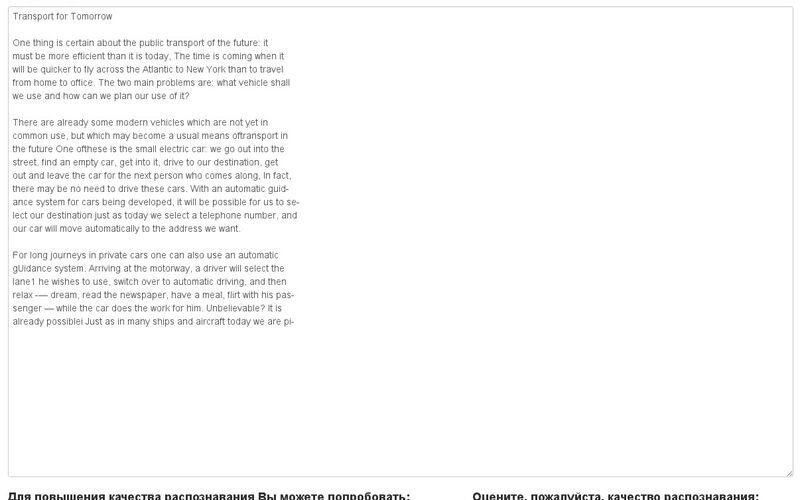
img2txt.com - это онлайн-сервис для распознавания текста, который позволяет получать текст с изображения или отсканированной страницы.